AI Inference Chips Revolution Transforms Real-Time AI
The artificial intelligence industry is witnessing a fundamental shift from training massive models to deploying them efficiently in real-world applications. This transformation has sparked a revolution in AI hardware, where specialized inference chips are emerging as the new battleground for achieving lightning-fast AI responses. Unlike traditional training-focused GPUs, these processors are engineered specifically for running AI models in production, delivering unprecedented speed and efficiency gains.
The stakes are enormous. When OpenAI's ChatGPT processes millions of queries daily, or when autonomous vehicles need split-second decision-making, every millisecond matters. Traditional graphics processing units, designed originally for rendering pixels, struggle with the unique demands of AI inference workloads. This gap has created opportunities for startups like Groq, which recently raised $640 million to challenge NVIDIA's dominance with their revolutionary Language Processing Unit technology.
Link to section: The Inference Bottleneck: Why Speed Matters More Than EverThe Inference Bottleneck: Why Speed Matters More Than Ever
AI inference represents the production phase of artificial intelligence, where trained models generate responses to user queries. Unlike training, which can take hours or days to complete, inference demands real-time performance. A chatbot user expects responses within seconds, not minutes. Autonomous vehicles require sensor data processing in microseconds to avoid collisions.
The challenge lies in the fundamental differences between training and inference workloads. Training involves parallel processing of massive datasets to adjust model parameters, leveraging the full parallel processing power of GPUs. Inference, however, typically processes single queries sequentially, requiring different architectural optimizations.
Consider the numbers: NVIDIA's H100 GPU, the gold standard for AI training, delivers impressive training performance but shows limitations in inference scenarios. When running a 70-billion parameter language model like Llama 2, traditional GPU-based systems might generate 30-50 tokens per second. For context, a token represents roughly three-quarters of a word, so generating a 100-word response takes several seconds.
This latency becomes problematic in production environments. Enterprise chatbots handling thousands of concurrent users experience queuing delays. Real-time applications like voice assistants feel sluggish. Gaming applications requiring AI-generated content suffer from noticeable pauses. These limitations have created demand for purpose-built inference processors.
Link to section: Groq's Revolutionary LPU ArchitectureGroq's Revolutionary LPU Architecture
Groq's Language Processing Unit represents a radical departure from conventional AI processors. Founded by Jonathan Ross, who previously developed Google's Tensor Processing Unit, the company has engineered the LPU from the ground up for inference workloads. The results speak for themselves: Groq's systems demonstrate 300 tokens per second on Llama 2 70B models, representing a 6-10x improvement over traditional GPU implementations.
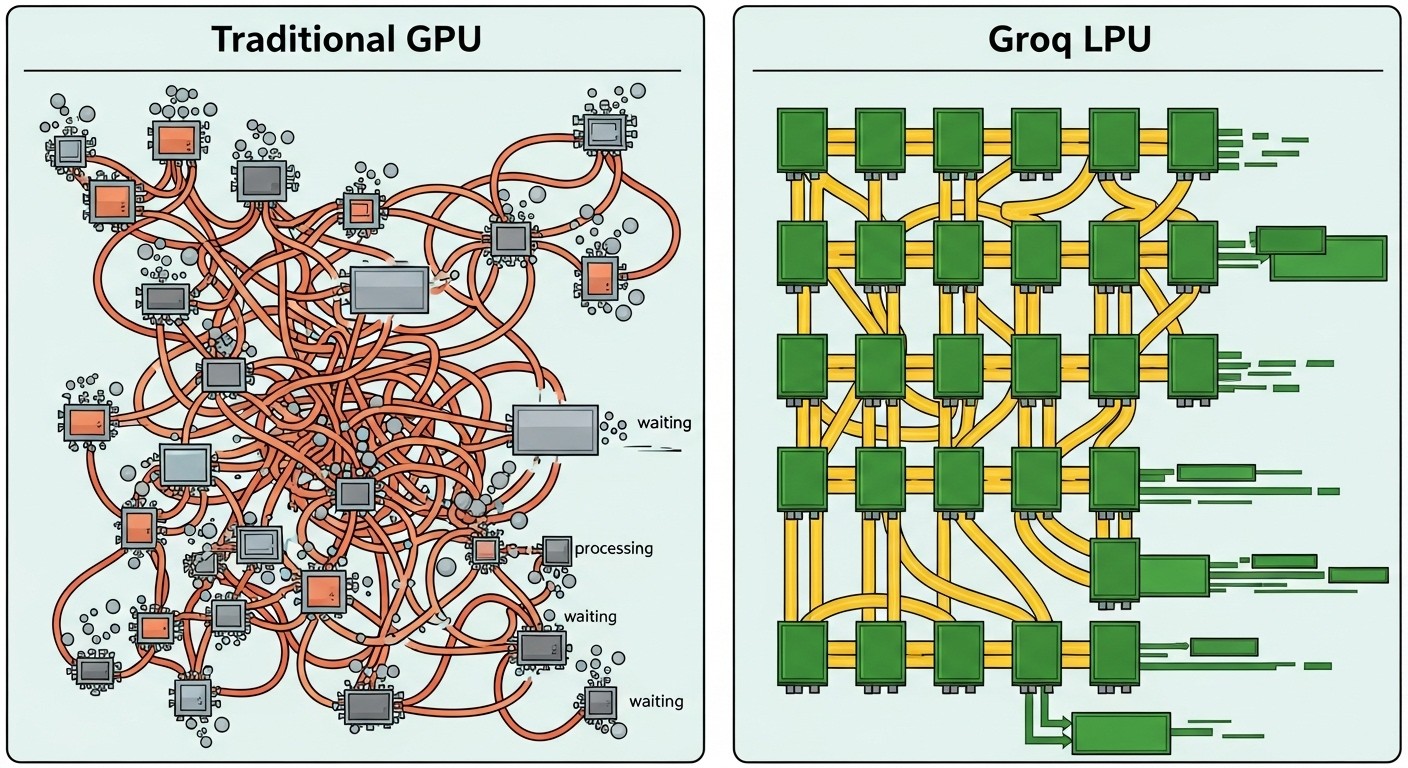
The LPU's architecture embodies four core design principles that differentiate it from GPUs. First, software-first design eliminates the hardware-software impedance mismatch common in GPU deployments. Traditional GPUs require complex software kernels to manage execution, introducing unpredictable latency. The LPU's software-first approach ensures deterministic performance.
Second, the programmable assembly line architecture processes AI workloads like a manufacturing assembly line. Unlike GPUs that juggle multiple tasks simultaneously, the LPU creates dedicated pathways for specific operations. Matrix multiplication, the core operation in neural networks, flows through optimized processing stages without competing for resources.
Third, deterministic compute and networking eliminate performance variability. GPU-based systems suffer from unpredictable execution times due to cache misses, memory contention, and scheduling overhead. The LPU guarantees consistent execution times, crucial for real-time applications.
Fourth, massive on-chip memory reduces external memory access bottlenecks. The LPU integrates 230 MB of high-speed SRAM directly on the processor, compared to traditional GPUs that rely heavily on slower external memory. This design delivers 80 TB/s of internal bandwidth, orders of magnitude faster than GPU memory subsystems.
The technical specifications highlight the LPU's inference optimization. Each processor delivers 750 TOPS at INT8 precision and 188 TeraFLOPS at FP16 precision. The architecture includes 5,120 Vector ALUs and a 320x320 fused dot product matrix multiplication unit, specifically sized for transformer model operations.
Link to section: Market Dynamics and Competitive LandscapeMarket Dynamics and Competitive Landscape
Groq's $640 million Series D funding round, led by BlackRock, validates the inference chip market's potential. The round valued the company at $2.8 billion, reflecting investor confidence in specialized AI processors. The funding enables Groq to scale production, targeting 100,000 deployed chips by Q1 2025 and 1.5 million by year-end.
The broader AI inference market is experiencing explosive growth. Market analysts project the AI edge computing market will surge from $9.1 billion in 2020 to $59.63 billion by 2030, representing a compound annual growth rate exceeding 20%. Edge AI software specifically is expected to reach $8.91 billion by 2030, growing at 28.8% annually.
This growth stems from fundamental shifts in AI deployment patterns. Companies are moving from cloud-based AI services to edge deployments for latency, privacy, and cost reasons. Edge inference reduces bandwidth requirements, improves response times, and keeps sensitive data local. These trends favor specialized inference processors over general-purpose GPUs.
Groq faces competition from multiple directions. NVIDIA continues evolving its inference capabilities, introducing optimizations like TensorRT for faster deployment. AMD is developing MI300 series processors targeting inference workloads. Intel's Gaudi 3 accelerators focus on cost-effective inference. Cloud hyperscalers like AWS, Google, and Microsoft are developing custom inference chips for their platforms.
Startups are also entering the market. Cerebras Systems offers wafer-scale processors for large-scale inference. d-Matrix focuses on AI-as-a-Service inference solutions. SambaNova Systems targets enterprise inference deployments. Each company approaches the inference challenge from different angles, creating a diverse ecosystem.
Link to section: The Shift from Training to Inference EconomicsThe Shift from Training to Inference Economics
The AI industry is experiencing a fundamental economic shift as inference workloads begin dominating computational requirements. While training large language models captures headlines with multi-million dollar compute budgets, inference represents the ongoing operational cost of AI deployment. A single popular AI service might serve millions of queries daily, creating massive inference demand.
This shift has profound implications for hardware requirements. Training workloads benefit from GPU architectures designed for parallel processing of large datasets. Inference workloads, processing individual queries, require different optimizations focused on latency and throughput rather than raw parallel computation.
The economic advantages of specialized inference chips become clear in production deployments. Groq claims their LPU systems cost one-tenth of equivalent GPU-based inference solutions while delivering superior performance. For companies serving millions of AI queries monthly, these cost savings translate to significant operational advantages.
Consider a practical example: a customer service chatbot handling 100,000 queries daily. Using traditional GPU-based inference, each query might cost $0.01 in compute resources, totaling $1,000 daily. Groq's LPU systems could potentially reduce this cost to $0.001 per query, saving $900 daily or $328,500 annually. These economics drive adoption of specialized inference hardware.
Link to section: Real-World Applications and Use CasesReal-World Applications and Use Cases
The practical applications for high-speed inference processing span numerous industries and use cases. In autonomous vehicles, Tesla's Hardware 4 platform demonstrates the critical importance of inference performance. The system processes camera and sensor data in real-time, making driving decisions within microseconds. Tesla's FSD Computer 2 delivers 50 TOPS of neural processing performance, specifically optimized for vision-based inference tasks.
Healthcare represents another critical application domain. Medical imaging systems require rapid analysis of CT scans, MRI images, and X-rays to assist diagnosis. Microsoft's AI diagnostic systems demonstrate 4x better performance than human doctors in certain scenarios, but only when inference latency remains below acceptable thresholds. Specialized inference chips enable real-time medical analysis that could save lives through faster diagnosis.
Manufacturing and industrial automation increasingly rely on computer vision for quality control, predictive maintenance, and process optimization. Edge AI systems deployed on factory floors need real-time inference capabilities to identify defects, predict equipment failures, and optimize production parameters. The harsh industrial environment and real-time requirements favor specialized inference processors over cloud-based solutions.
Financial services leverage high-speed inference for fraud detection, algorithmic trading, and risk assessment. Trading systems require microsecond latency to capitalize on market opportunities. Credit card fraud detection systems must analyze transactions in real-time to prevent fraudulent charges. These applications demand the deterministic performance characteristics offered by specialized inference chips.
Gaming and entertainment applications are emerging as significant inference markets. Real-time AI-generated content, including procedural world generation, dynamic NPC behavior, and personalized experiences, requires low-latency inference. Cloud gaming services need efficient inference to deliver AI-enhanced graphics and gameplay features without introducing noticeable delays.
Link to section: Technical Architecture Deep DiveTechnical Architecture Deep Dive
Understanding the technical differences between training and inference processors reveals why specialized chips like Groq's LPU deliver superior performance. Traditional GPUs excel at training through massive parallel processing capabilities, handling thousands of operations simultaneously. The NVIDIA H100, for example, includes 16,896 CUDA cores capable of parallel execution across large datasets.
Inference workloads, however, typically process single queries with sequential operations. A language model generating text processes tokens one at a time, with each token generation dependent on previous outputs. This sequential nature limits the benefits of massive parallelism while emphasizing the importance of low-latency execution.
Memory architecture represents another critical difference. Training workloads can tolerate longer memory access times because they process large batches of data. Inference workloads, processing individual queries, suffer significantly from memory latency. Groq's LPU addresses this challenge with 230 MB of on-chip SRAM, providing 80 TB/s of bandwidth compared to GPU external memory systems delivering 1-3 TB/s.
The deterministic execution model further differentiates inference-optimized processors. GPU execution times vary based on workload characteristics, memory access patterns, and resource contention. These variations create unpredictable latency, problematic for real-time applications. The LPU's assembly line architecture ensures consistent execution times regardless of input characteristics.
Precision requirements also differ between training and inference. Training typically requires FP32 or FP16 precision to maintain gradient accuracy during backpropagation. Inference can often utilize lower precision formats like INT8 or even INT4 without significant accuracy loss. Specialized inference chips optimize for these lower precision formats, achieving higher throughput and energy efficiency.
Link to section: Edge Computing Integration and 5G EnablementEdge Computing Integration and 5G Enablement
The proliferation of edge computing infrastructure amplifies demand for efficient inference processors. Edge deployments bring AI capabilities closer to data sources, reducing latency and bandwidth requirements while improving privacy and security. However, edge environments impose strict constraints on power consumption, physical size, and cooling requirements that favor specialized inference chips over power-hungry GPUs.
5G networks are accelerating edge AI adoption by providing the high-speed, low-latency connectivity required for distributed inference systems. With 5G delivering data speeds up to 100 times faster than 4G networks, edge AI systems can seamlessly integrate with cloud resources while maintaining real-time performance. This hybrid edge-cloud architecture enables sophisticated AI applications that would be impossible with pure cloud or pure edge deployments.
The ongoing battle between edge and cloud computing is reshaping AI deployment strategies, with inference optimization playing a crucial role in determining which applications benefit from edge deployment versus cloud-based processing.
The Internet of Things ecosystem represents a massive market for edge inference processors. Smart cameras, autonomous vehicles, industrial sensors, and consumer devices increasingly incorporate AI capabilities. These applications require efficient inference processors that deliver AI performance within tight power and cost budgets. The edge AI software market is projected to grow from $1.95 billion in 2024 to $8.91 billion by 2030, driven largely by IoT applications.
Healthcare edge deployments demonstrate the potential of specialized inference chips. Wearable devices monitoring patient health require real-time analysis of sensor data to detect anomalies and trigger alerts. These devices must operate for days or weeks on battery power while providing continuous AI-powered monitoring. Specialized inference chips enable sophisticated health monitoring applications that would be impossible with traditional processors.
Link to section: Developer Experience and Ecosystem ChallengesDeveloper Experience and Ecosystem Challenges
The success of specialized inference chips depends heavily on developer adoption and ecosystem support. NVIDIA's dominance in AI hardware stems partly from their comprehensive software ecosystem, including CUDA development tools, cuDNN libraries, and TensorRT optimization frameworks. New inference chip providers must develop comparable software ecosystems to attract developers.
Groq addresses this challenge by focusing on cloud-based deployment initially. Rather than selling chips directly to developers, Groq provides cloud services accessible through standard APIs. Their GroqCloud platform has grown from a few developers to 350,000 users, demonstrating the appeal of high-performance inference services. This approach reduces barriers to adoption while building developer mindshare.
The company's strategy acknowledges the complexity of hardware deployment. As Groq CEO Jonathan Ross explained, "We found it hard to sell hardware because you couldn't viscerally experience it." Cloud deployment allows developers to experience the performance benefits immediately without hardware integration challenges.
However, cloud-first strategies have limitations. Edge applications require local inference capabilities that cloud services cannot provide. Enterprise deployments often prefer on-premises hardware for security and latency reasons. Long-term success requires supporting both cloud and on-premises deployment models.
Software compatibility represents another ecosystem challenge. Existing AI applications are often optimized for GPU architectures using frameworks like PyTorch and TensorFlow. Porting applications to specialized inference chips may require code modifications and reoptimization. Chip providers must minimize these migration barriers through compatibility layers and automated optimization tools.
Link to section: Future Outlook and Industry ImplicationsFuture Outlook and Industry Implications
The AI inference chip revolution is still in its early stages, with significant developments expected over the next several years. Market consolidation seems inevitable as successful architectures gain adoption while less competitive approaches fade. The high capital requirements for chip development and manufacturing favor companies with substantial funding and technical expertise.
Tesla's roadmap illustrates the rapid evolution of inference hardware. The company plans to introduce Hardware 5 in January 2026, targeting 10x the performance of current Hardware 4 systems. This aggressive timeline reflects the critical importance of inference performance for autonomous vehicle applications. Tesla's vertical integration strategy, developing both hardware and software internally, may become a model for other companies requiring specialized inference capabilities.
The emergence of AI-specific processors may challenge traditional semiconductor companies. Intel, AMD, and NVIDIA must adapt their roadmaps to address inference-optimized requirements. Intel's struggles with AI chip development, including recent leadership changes, highlight the challenges facing established companies in this rapidly evolving market.
Startup opportunities remain significant despite the high barriers to entry. Specialized applications like quantum computing simulation, bioinformatics analysis, and scientific modeling may benefit from domain-specific inference architectures. Companies addressing these niche markets could achieve success similar to Groq's broader inference focus.
International competition is intensifying as countries recognize the strategic importance of AI hardware capabilities. China's significant investments in AI chip development, South Korea's $72 billion AI investment fund, and government initiatives worldwide reflect the geopolitical implications of AI hardware leadership.
The inference chip revolution represents more than a technical evolution; it signals AI's maturation from research curiosity to production necessity. As AI applications become ubiquitous across industries, the processors powering these applications will largely determine their success. Companies that master inference optimization will gain competitive advantages in the AI-driven economy, while those relying on legacy architectures may find themselves at significant disadvantages.
The next few years will likely determine which approaches succeed in the inference processor market. Groq's impressive funding and technical achievements position them as a serious challenger to established players, but execution remains critical. The ultimate winners will be companies that combine technical innovation with practical deployment strategies, creating the infrastructure for AI's continued transformation of business and society.

