GraphRAG Revolution: Why Knowledge Graphs Beat Vector Search

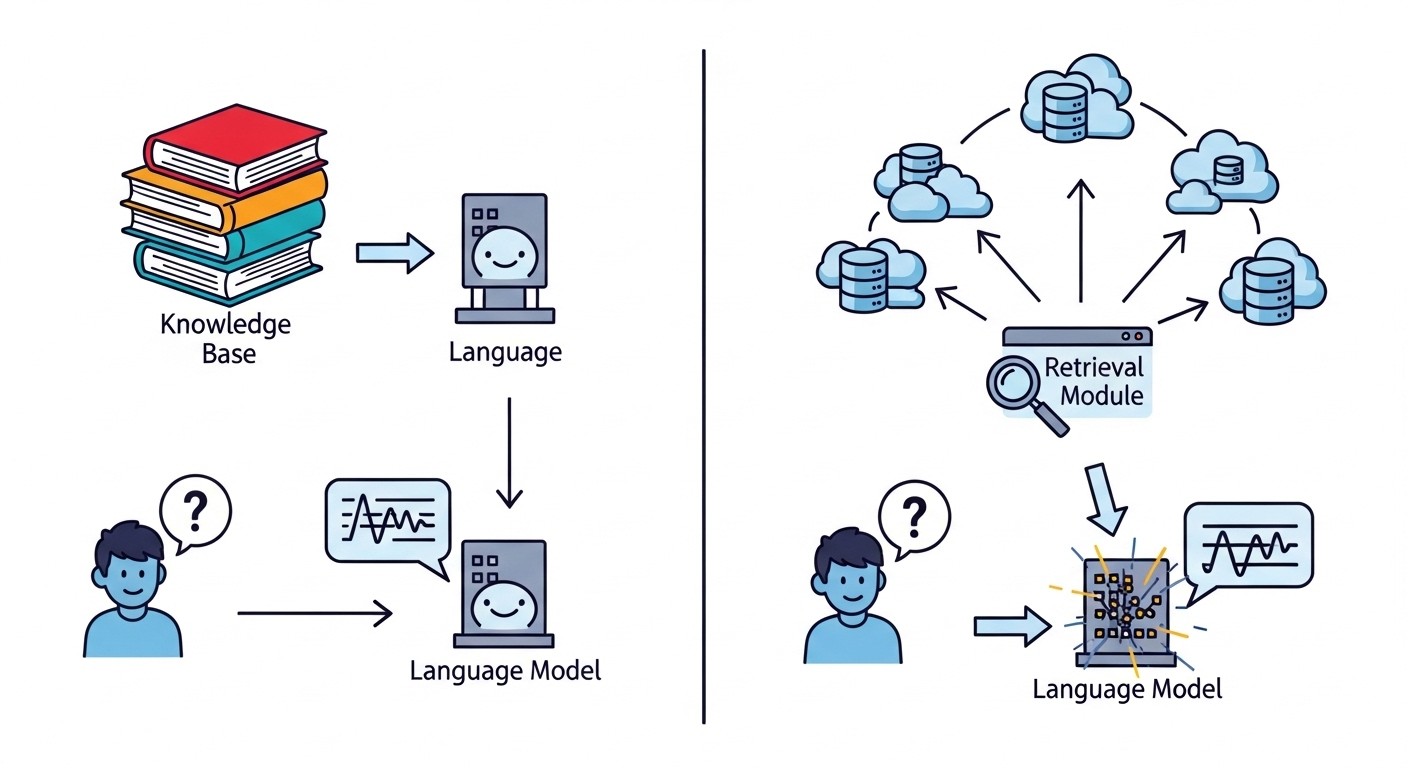
The enterprise AI revolution has hit a wall. Companies spent millions building RAG systems that promised to unlock their knowledge bases, only to discover a fundamental limitation: traditional vector search simply cannot handle the complex, interconnected nature of enterprise data. While these systems excel at finding similar documents, they fail spectacularly when users need answers that require understanding relationships, context, and multi-hop reasoning across different data sources.
Enter GraphRAG, a paradigm shift that replaces the document-centric approach of traditional RAG with sophisticated knowledge graphs. Instead of treating information as isolated chunks floating in vector space, GraphRAG builds comprehensive maps of entities, relationships, and hierarchies within organizational data. The results speak for themselves: GraphRAG systems achieve 80% accuracy on complex enterprise queries compared to traditional RAG's 50.83%, with some implementations reaching over 90% accuracy in structured domains.
This transformation represents more than incremental improvement. It fundamentally changes how AI systems understand and retrieve information, moving from similarity-based search to relationship-aware reasoning. Companies like Microsoft, Lettria, and numerous enterprise solution providers are rapidly adopting GraphRAG architectures, recognizing that the future of enterprise AI depends on systems that can truly comprehend the interconnected nature of business knowledge.
Link to section: The Fatal Flaw in Traditional RAG ArchitectureThe Fatal Flaw in Traditional RAG Architecture
Traditional RAG operates on a deceptively simple premise: convert documents into vector embeddings, store them in a database, and retrieve semantically similar chunks when users ask questions. This approach works admirably for straightforward queries like "What is our vacation policy?" but collapses when faced with the multi-faceted questions that define real enterprise scenarios.
The core problem lies in how traditional RAG processes information. Documents get chunked into fixed-size segments, typically 500-1000 tokens, and each chunk receives an independent vector embedding. This chunking process inevitably destroys crucial context that spans multiple paragraphs or sections. When a user asks "Compare the oldest booked Amazon revenue to the most recent," a traditional RAG system must somehow piece together information scattered across different document chunks, often missing the connections entirely.
Vector similarity search compounds this limitation by retrieving chunks based purely on semantic similarity to the query. While this works for finding documents about similar topics, it cannot identify the specific relationships between entities that enterprise queries often require. A query about supply chain relationships might retrieve documents about suppliers and documents about products, but miss the critical connections between specific suppliers and affected products.
The chunking strategy creates additional problems with entity resolution and disambiguation. When the same entity appears in multiple chunks under different names or contexts, traditional RAG treats them as separate items rather than recognizing them as the same entity with different attributes or relationships. This fragmentation makes it nearly impossible to build comprehensive answers that require aggregating information about specific entities across multiple sources.
Perhaps most critically, traditional RAG systems lack any mechanism for reasoning about relationships or hierarchies within the data. They cannot understand that Person A reports to Person B, that Product X depends on Component Y, or that Policy Z supersedes Policy W. These relationship-based insights are precisely what make enterprise knowledge valuable, yet they remain invisible to vector-based retrieval systems.
Link to section: How GraphRAG Transforms Information ArchitectureHow GraphRAG Transforms Information Architecture
GraphRAG addresses these fundamental limitations by constructing explicit knowledge graphs that capture entities, relationships, and hierarchical structures within enterprise data. Instead of chunking documents and hoping for the best, GraphRAG systems perform sophisticated entity extraction and relationship mapping to build comprehensive representations of organizational knowledge.
The process begins with advanced natural language processing that identifies entities such as people, organizations, products, policies, dates, and locations within documents. But GraphRAG goes far beyond simple named entity recognition. It extracts relationships between entities, understanding that John Smith "manages" the Marketing Department, that Product A "depends on" Supplier B, and that Policy Version 2.1 "supersedes" Policy Version 2.0.
These entities and relationships form nodes and edges in a knowledge graph that preserves the contextual connections that traditional chunking destroys. When a user asks about supply chain risks, GraphRAG can traverse the graph to find all products connected to a specific supplier, then identify customers affected by those products, and finally surface relevant risk mitigation policies—all while maintaining the logical connections that justify the complete answer.
Microsoft's GraphRAG implementation takes this approach even further by incorporating hierarchical community detection. The system uses clustering algorithms to identify communities of related entities and generates summaries for each community that capture emergent themes and patterns spanning multiple documents. These community summaries enable GraphRAG to handle broad, strategic queries that require understanding high-level patterns across the entire knowledge base.
The knowledge graph structure also enables multiple query strategies that traditional RAG cannot support. Global searches leverage community summaries for broad questions about organizational themes or patterns. Local searches focus on specific entities by traversing their immediate neighborhood in the graph. Hybrid approaches can combine both strategies, using global context to inform local entity-focused retrieval.
Link to section: Technical Implementation and Architecture DetailsTechnical Implementation and Architecture Details
Building production GraphRAG systems requires carefully orchestrating multiple sophisticated components that work together to extract, structure, and query enterprise knowledge. The implementation typically follows a two-phase architecture: an indexing phase that constructs the knowledge graph and a querying phase that leverages the graph for information retrieval.
The indexing phase begins with document ingestion and preprocessing, but unlike traditional RAG, the focus shifts immediately to entity and relationship extraction. Advanced language models like GPT-4 or specialized NER models identify entities within documents, while relationship extraction models determine connections between entities. This process often requires domain-specific tuning to achieve high precision in enterprise contexts where terminology and relationships may be highly specialized.
Entity resolution represents one of the most complex challenges in GraphRAG implementation. The same person might be referenced as "John Smith," "J. Smith," "John," or "Director of Marketing" across different documents. Graph construction algorithms must identify these references as the same entity and merge their attributes appropriately. Fuzzy matching algorithms, often enhanced with machine learning models trained on organizational data patterns, handle this disambiguation process.
The actual graph construction leverages sophisticated algorithms for community detection and hierarchy building. The Leiden algorithm, commonly used in GraphRAG implementations, identifies clusters of densely connected entities that represent natural organizational or topical boundaries. These communities receive automatically generated summaries that capture their key themes, relationships, and significance within the broader knowledge base.
Query processing in GraphRAG environments involves multiple retrieval strategies working in concert. Cypher queries against graph databases like Neo4j enable precise traversal of entity relationships. Vector similarity searches against entity embeddings provide semantic matching capabilities. Hybrid ranking algorithms combine graph-based relevance scores with traditional similarity metrics to optimize retrieval precision.
The Lettria implementation demonstrates how these components integrate in practice. Their hybrid approach maintains both a knowledge graph and vector embeddings, using fallback mechanisms to ensure robust performance across different query types. When GraphRAG can identify explicit relationships relevant to a query, it leverages graph traversal for precision. When queries involve more abstract or poorly structured information, the system falls back to vector similarity search while still benefiting from the entity-aware context that the knowledge graph provides.
Link to section: Performance Benchmarks and Real-World ResultsPerformance Benchmarks and Real-World Results
The performance advantages of GraphRAG over traditional approaches are substantial and well-documented across multiple independent evaluations. Lettria's comprehensive benchmark study, comparing their GraphRAG implementation against Weaviate's Verba baseline system, provides the most detailed analysis of real-world performance across diverse enterprise scenarios.
Testing across datasets from finance, healthcare, aerospace, and regulatory domains, GraphRAG achieved 80% correct answers compared to traditional RAG's 50.83%. When including partially correct but acceptable answers, GraphRAG's accuracy rose to nearly 90% while vector-only approaches reached just 67.5%. These results become even more pronounced in domains requiring complex technical understanding, where GraphRAG provided 90.63% correct answers in aerospace technical specifications versus traditional RAG's 46.88%.
The benchmark methodology focused on six distinct query types that represent common enterprise information needs: fact-based queries, multi-hop reasoning tasks, numerical comparisons, tabular data extraction, temporal analysis, and multi-constraint queries. GraphRAG demonstrated consistent advantages across all categories, but showed particularly strong performance on multi-hop queries that require traversing relationships between multiple entities.
Response time analysis reveals another critical advantage. While traditional RAG systems often struggle with complex queries requiring multiple retrieval iterations, GraphRAG systems maintain sub-second response times even for complex multi-entity queries. The graph structure enables efficient traversal algorithms that can quickly identify relevant entity neighborhoods without exhaustive similarity searches across large document collections.
FalkorDB's analysis of enterprise-specific queries provides additional validation of GraphRAG's advantages. Their study of 43 enterprise queries across four categories (day-to-day analytics, operational analytics, metrics and KPIs, strategic planning) showed even more dramatic improvements. LLM systems without knowledge graph grounding achieved only 16.7% accuracy, while GraphRAG approaches reached 56.2% accuracy—a 3.4x improvement that represents the difference between unusable and production-ready performance levels.
The accuracy gains become more pronounced as query complexity increases. For queries involving five or more distinct entities, traditional vector RAG accuracy degrades to near zero, while GraphRAG maintains stable performance even with 10+ entities per query. This pattern reflects the fundamental architectural advantage of explicit relationship modeling over similarity-based retrieval.
Link to section: Implementation Strategies and Development ApproachesImplementation Strategies and Development Approaches
Successfully deploying GraphRAG in enterprise environments requires navigating several implementation pathways, each with distinct advantages and complexity tradeoffs. Organizations can choose between building custom solutions using open-source components, leveraging managed platforms, or adopting hybrid approaches that balance control with operational complexity.
The Microsoft GraphRAG open-source implementation provides the most comprehensive starting point for organizations willing to invest in custom development. Available through GitHub with Apache 2.0 licensing, the system includes complete pipelines for entity extraction, relationship mapping, community detection, and query processing. The implementation supports integration with Azure OpenAI services for entity extraction and uses Neo4j or similar graph databases for knowledge storage.
Setting up Microsoft GraphRAG requires configuring several key components through YAML configuration files. The extraction pipeline uses customizable prompts for entity identification and relationship extraction, allowing organizations to tune the system for domain-specific terminology and relationship patterns. Community detection parameters control how the system identifies entity clusters and generates community summaries, with settings for resolution, randomization, and iteration limits.
from graphrag import GraphRAGPipeline
from graphrag.config import GraphRAGConfig
# Initialize GraphRAG with custom configuration
config = GraphRAGConfig(
entity_extraction_model="gpt-4",
relationship_extraction_model="gpt-4",
community_detection_algorithm="leiden",
embedding_model="text-embedding-3-large",
chunk_size=500,
chunk_overlap=50
)
# Create and run the indexing pipeline
pipeline = GraphRAGPipeline(config)
pipeline.build_graph(documents_path="/path/to/documents")For organizations seeking managed solutions, platforms like Lettria, webAI, and FalkorDB offer GraphRAG-as-a-Service implementations. These platforms handle the operational complexity of graph construction and maintenance while providing APIs for integration with existing enterprise systems. webAI's implementation specifically targets multimodal document processing, combining vision and language models to extract structured information from complex documents containing both text and visual elements.
The choice between approaches often depends on organizational constraints around data privacy, customization requirements, and operational resources. Custom implementations provide maximum control and customization but require significant ML engineering expertise. Managed platforms reduce operational overhead but may limit customization options and require external data processing agreements.
Hybrid approaches represent an increasingly popular middle ground. Organizations begin with managed platforms or pre-built solutions for proof-of-concept development, then gradually build internal capabilities for production deployment. This pathway allows teams to validate GraphRAG value propositions without major upfront investments while building the expertise needed for eventual custom implementation.
Link to section: Enterprise Applications and Use CasesEnterprise Applications and Use Cases
GraphRAG's ability to reason about relationships and hierarchies makes it particularly valuable for enterprise applications that require connecting information across organizational silos. Financial services organizations leverage GraphRAG for risk assessment workflows that must trace connections between customers, products, regulatory requirements, and market conditions. Traditional RAG systems cannot effectively map these multi-layered relationships, while GraphRAG excels at providing comprehensive risk profiles that account for direct and indirect exposures.
Customer service applications represent another natural fit for GraphRAG capabilities. When customers contact support with complex issues involving multiple products, services, or historical interactions, GraphRAG systems can traverse customer relationship graphs to provide complete context to service representatives. The system can identify all products associated with a customer account, trace the history of previous support interactions, and surface relevant policies or procedures—all while maintaining the logical connections that justify specific recommendations.
Legal and compliance applications benefit significantly from GraphRAG's ability to understand regulatory hierarchies and precedent relationships. Legal research queries like "Find all regulations that superseded the 2019 data privacy guidelines and identify affected business processes" require understanding temporal relationships, regulatory hierarchies, and process dependencies that traditional RAG cannot effectively model. Advanced database architectures supporting these complex relationship queries become essential infrastructure for legal tech applications.
Supply chain management represents perhaps the most compelling GraphRAG application area. Modern supply chains involve complex networks of suppliers, components, manufacturers, distributors, and customers with intricate dependency relationships. When supply chain disruptions occur, organizations need to quickly identify all affected products, customers, and alternative sourcing options. GraphRAG systems can traverse supplier relationship graphs to provide comprehensive impact analyses that account for multi-level dependencies and alternative pathway options.
Healthcare organizations utilize GraphRAG for patient care coordination scenarios involving multiple specialists, treatment histories, medication interactions, and care plan dependencies. A query about treatment options for a patient with multiple comorbidities requires understanding relationships between conditions, medications, specialists, and treatment protocols that span multiple medical records and knowledge sources.
Link to section: The Competitive Landscape and Future DirectionsThe Competitive Landscape and Future Directions
The GraphRAG ecosystem is rapidly evolving with multiple vendors and open-source projects competing to define the standard implementation approaches. Microsoft's research-driven GraphRAG implementation focuses on academic rigor and comprehensive feature sets, making it ideal for organizations with strong ML engineering capabilities. The open-source approach encourages experimentation and customization but requires significant technical investment.
Commercial platforms are differentiating through specialized capabilities and integration options. Lettria emphasizes hybrid retrieval that gracefully falls back from graph search to vector search when needed, ensuring robust performance across diverse query types. webAI focuses on multimodal document processing capabilities that extract structured information from complex documents containing both text and visual elements. FalkorDB optimizes for high-performance graph operations with specialized database architectures designed specifically for knowledge graph workloads.
The vector database ecosystem is adapting to GraphRAG requirements through enhanced relationship modeling capabilities. Traditional vector database providers are adding graph functionality to remain competitive, while specialized graph databases are improving vector search capabilities. This convergence suggests that future implementations may seamlessly blend graph and vector approaches rather than treating them as distinct architectural choices.
Several technical developments are likely to reshape GraphRAG capabilities over the next few years. Automated schema discovery could eliminate much of the manual ontology design currently required for domain-specific implementations. Real-time graph updates will enable GraphRAG systems to maintain current knowledge bases without complete reindexing cycles. Multi-modal graph construction will incorporate information from images, videos, and other media types into unified knowledge representations.
Edge computing deployments represent another frontier for GraphRAG development. As organizations seek to process sensitive information locally, edge-optimized graph databases and compact language models will enable on-premises GraphRAG implementations. This capability becomes particularly important for healthcare, financial services, and government applications where data privacy regulations prohibit cloud-based processing.
Link to section: Building Production GraphRAG SystemsBuilding Production GraphRAG Systems
Deploying GraphRAG in production environments requires careful attention to operational concerns that extend far beyond the core algorithmic capabilities. Graph database selection significantly impacts performance, scalability, and maintenance requirements. Neo4j provides comprehensive graph query capabilities and mature operational tooling, but requires specialized database administration expertise. Amazon Neptune offers managed graph database services with built-in scalability and backup capabilities, reducing operational overhead at the cost of some customization flexibility.
Data pipeline design becomes particularly crucial for GraphRAG systems because knowledge graphs require more sophisticated preprocessing than traditional RAG document chunking. Entity extraction accuracy depends heavily on consistent text preprocessing, tokenization, and domain-specific terminology handling. Organizations often need to develop custom preprocessing pipelines that account for document format variations, multilingual content, and domain-specific entity types.
Graph maintenance strategies must account for the dynamic nature of enterprise knowledge. Unlike traditional RAG systems where document updates simply replace vector embeddings, GraphRAG updates require careful entity resolution and relationship merging. When a document containing information about existing entities gets updated, the system must determine whether to update existing graph nodes or create new ones, and how to handle potentially conflicting information.
Performance optimization for production GraphRAG involves multiple considerations. Graph query optimization requires understanding common query patterns and designing indices appropriately. Entity embedding strategies must balance semantic richness with computational efficiency. Community detection algorithms need tuning for specific knowledge domains and organizational structures.
Security and access control implementations for GraphRAG systems must account for both document-level and entity-level permissions. Traditional RAG systems can apply document-level access controls during retrieval, but GraphRAG systems may need to filter graph traversals based on user permissions for specific entities or relationships. This fine-grained access control significantly complicates both the technical implementation and the operational management of production systems.
The future of enterprise AI increasingly depends on systems that can understand and reason about the complex relationships that define organizational knowledge. GraphRAG represents a fundamental architectural shift from similarity-based retrieval to relationship-aware reasoning, delivering accuracy improvements that transform AI from interesting experiment to indispensable business tool. Organizations investing in GraphRAG capabilities today position themselves to leverage the full value of their knowledge assets in an increasingly AI-driven competitive landscape.

