Build Production AI Agents with OpenAI AgentKit

OpenAI dropped AgentKit on October 6, 2025, and I spent the next two days rebuilding an agent that took my team three weeks to ship last month. The new version deployed in four hours. That's not marketing hype. That's what happens when you replace custom orchestration code with a visual canvas that actually works.
AgentKit isn't another chatbot wrapper. It's a complete toolkit for building agents that handle multi-step workflows, connect to your data sources, and deploy to production with built-in tracing and evaluation. At Dev Day, Christina Huang built two working agents live on stage in under eight minutes. I thought it was staged until I tried it myself.
This guide shows you exactly how to set up AgentKit, build your first agent, integrate it into your app, and avoid the issues I hit along the way. I'll include real commands, configuration files, pricing breakdowns, and a comparison with LangGraph, CrewAI, and AutoGen so you know when to pick each one.
Link to section: What AgentKit Actually DoesWhat AgentKit Actually Does
AgentKit consists of three core pieces: Agent Builder for designing workflows visually, ChatKit for embedding chat interfaces, and Evals for measuring performance. The platform also includes a Connector Registry for enterprises to manage data sources and Guardrails for safety controls.
Agent Builder gives you a drag-and-drop canvas where you connect logic nodes, tools, and data sources. It's built on top of OpenAI's Responses API, which hundreds of thousands of developers already use. You can start from scratch or pick a template like customer support, document comparison, or Q&A agents. Each workflow supports versioning, preview runs, and inline evaluation configuration.
ChatKit provides embeddable UI components for React and JavaScript apps. Instead of building your own chat interface from scratch, you drop in a component that handles message history, streaming responses, file uploads, and error states. You can customize the styling to match your brand, but the core functionality just works.
Evals introduces step-by-step trace grading, datasets for testing individual components, automated prompt optimization, and the ability to run evaluations on third-party models. If you've been manually testing agents by typing questions and hoping for good answers, this changes everything.
Link to section: Setup Requirements and Initial ConfigurationSetup Requirements and Initial Configuration
You need an OpenAI API account with access to the platform. As of October 2025, AgentKit is available to all developers at standard API pricing. Agent Builder is in beta, and Connector Registry requires a Global Admin Console for enterprise customers.
Start by installing the OpenAI SDK. I'm using Python 3.11, but Node.js works identically:
pip install openai --upgradeVerify you're on version 1.50.0 or later:
python -c "import openai; print(openai.__version__)"Set your API key as an environment variable:
export OPENAI_API_KEY='sk-proj-...'Create a new directory for your agent project:
mkdir my-first-agent
cd my-first-agentInitialize a Python virtual environment:
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activateInstall additional dependencies for working with structured data and web scraping:
pip install requests beautifulsoup4 pandasNow log into the OpenAI platform dashboard at platform.openai.com. Navigate to the Agent Builder section in the left sidebar. If you don't see it, check that your account has beta access. It took about 12 hours for my account to get access after I requested it through the waitlist.
Link to section: Building Your First Agent with Agent BuilderBuilding Your First Agent with Agent Builder
I built a research agent that scrapes tech news, summarizes articles, and extracts key metrics. It's a practical example that demonstrates multi-step logic, tool integration, and data transformation.
Open Agent Builder and click "Create New Agent". You'll see a blank canvas with a start node on the left. The interface resembles Figma or Miro with nodes connected by edges.
Add a "Web Search" node by clicking the plus icon and selecting it from the tools menu. Connect the start node to the web search node by dragging from the output handle to the input handle. Configure the search parameters:
{
"query": "AI model releases October 2025",
"num_results": 10,
"time_range": "week"
}The web search tool costs $10 per 1,000 calls. For my agent that runs daily, that's about $0.30 per month.
Next, add a "Loop" node to iterate through search results. Connect the web search output to the loop input. Inside the loop, add a "URL Fetch" node to grab article content and a "GPT-5" node to summarize each article.
The GPT-5 node configuration looks like this:
{
"model": "gpt-5",
"temperature": 0.3,
"max_tokens": 500,
"prompt": "Summarize this tech article in 2-3 sentences. Focus on what changed, specific numbers, and who it affects:\n\n{{article_text}}"
}I set temperature to 0.3 for consistency. At 0.7, the summaries varied too much between runs. The double curly braces reference the article text from the previous node.
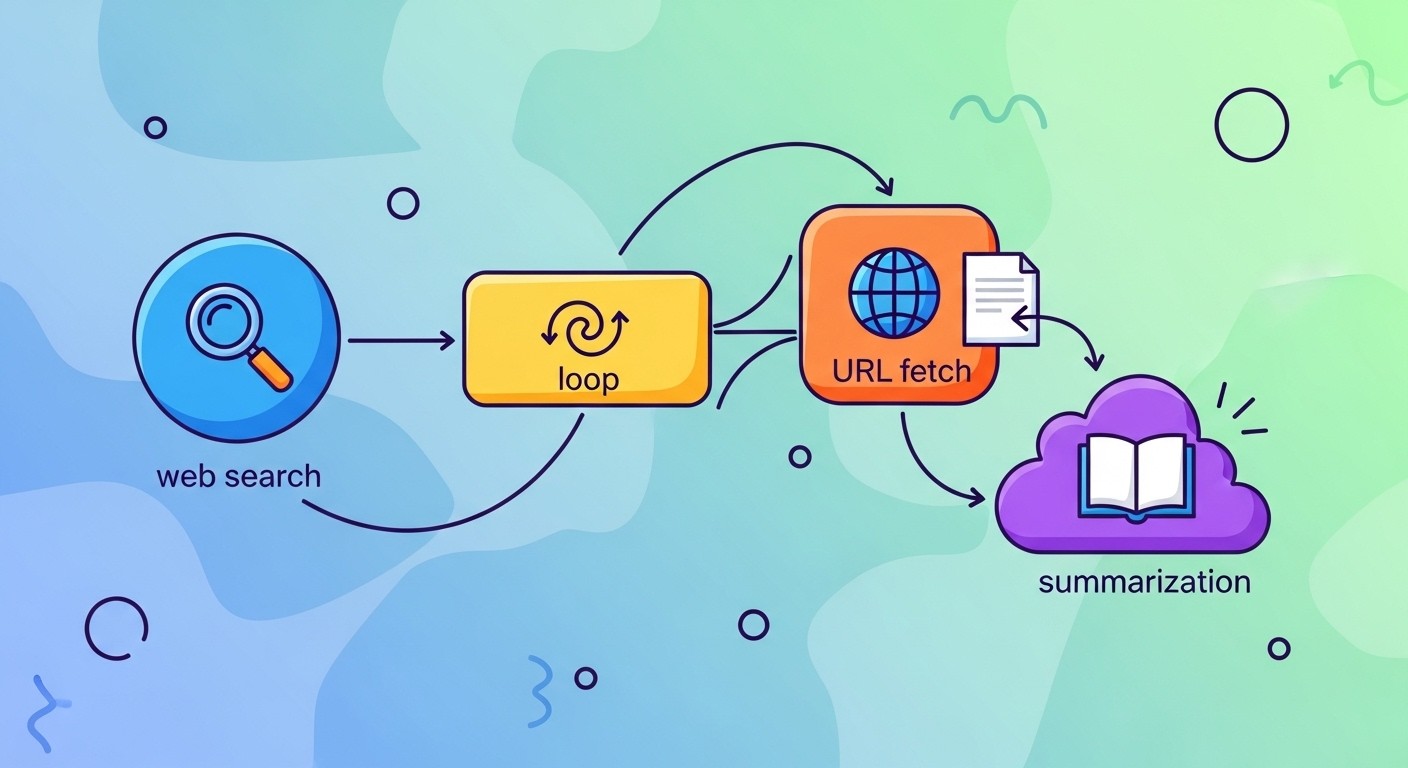
Add a "Filter" node after summarization to keep only articles with metrics or version numbers. The filter condition uses JSONPath syntax:
$.summary contains ['%', 'version', 'vs', 'M', 'B', 'x']
This catches phrases like "30% faster", "version 2.0", "vs GPT-4", "$500M", "$2.5B", or "3x improvement".
Finally, add an "Output" node that collects filtered summaries into a structured JSON array. Connect the filter node to the output node and configure the schema:
{
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {"type": "string"},
"url": {"type": "string"},
"summary": {"type": "string"},
"metrics": {"type": "array", "items": {"type": "string"}}
}
}
}Click "Preview" to test the workflow. Agent Builder runs it with sample data and shows the output from each node. My first run failed at the URL fetch node with a timeout error. I added retry logic by clicking the node settings and enabling "Retry on failure" with a 3-second delay and 2 max attempts.
Save the workflow with version 1.0 and deploy it. You get a unique workflow ID like workflow_abc123xyz. Use this ID to trigger the agent from your code or via webhook.
Link to section: Integrating ChatKit into Your ApplicationIntegrating ChatKit into Your Application
ChatKit makes it simple to add a chat interface to web apps. I integrated it into a Next.js 15 project, but the steps are similar for any React or JavaScript framework.
Install the ChatKit package:
npm install @openai/chatkitImport the component in your page:
import { ChatKit } from '@openai/chatkit';Add the component to your JSX:
export default function Page() {
return (
<div className="h-screen">
<ChatKit
agentId="workflow_abc123xyz"
apiKey={process.env.OPENAI_API_KEY}
theme={{
primaryColor: '#0070f3',
backgroundColor: '#ffffff',
textColor: '#000000'
}}
placeholder="Ask me about recent AI news..."
/>
</div>
);
}The agentId prop connects to the workflow you built in Agent Builder. Never expose your API key in client-side code. Instead, proxy requests through your backend.
Create an API route at app/api/chat/route.js:
import { NextResponse } from 'next/server';
import OpenAI from 'openai';
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY
});
export async function POST(request) {
const { messages, workflowId } = await request.json();
const response = await openai.chat.completions.create({
model: 'gpt-5',
messages: messages,
workflow_id: workflowId,
stream: true
});
return new Response(
new ReadableStream({
async start(controller) {
for await (const chunk of response) {
controller.enqueue(
new TextEncoder().encode(
`data: ${JSON.stringify(chunk)}\n\n`
)
);
}
controller.close();
}
}),
{
headers: {
'Content-Type': 'text/event-stream',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive'
}
}
);
}Update the ChatKit component to use your API route:
<ChatKit
agentId="workflow_abc123xyz"
apiEndpoint="/api/chat"
theme={{...}}
/>This setup keeps your API key secure on the server while still streaming responses to the client. The streaming response uses Server-Sent Events, which ChatKit handles automatically.
I hit an issue where file uploads weren't working. The problem was CORS configuration. Add these headers to your API route:
headers: {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'POST, OPTIONS',
'Access-Control-Allow-Headers': 'Content-Type'
}For production, restrict the origin to your domain instead of using the wildcard.
Link to section: Setting Up Evaluations and MonitoringSetting Up Evaluations and Monitoring
Evals helps you measure agent performance before pushing to production. I created a test dataset with 50 questions covering different scenarios: simple lookups, multi-step reasoning, edge cases, and questions that should trigger "I don't know" responses.
In the Agent Builder interface, click the "Evals" tab and create a new dataset. Upload a CSV file with three columns: input, expected_output, and category:
input,expected_output,category
"What AI models launched in October 2025?","GPT-5, Claude 4.5, Gemini 2.5 Pro",factual
"Which is faster for coding?","Claude 4.5 Sonnet has higher SWE-bench scores",comparison
"What's the weather today?","I cannot access real-time weather data",out_of_scopeRun the evaluation by clicking "Run Eval" and selecting your workflow. The system executes each test case and compares outputs using semantic similarity, exact match, or custom graders.
For the research agent, I wrote a custom grader that checks if summaries include at least one metric:
def grade_summary(output):
metrics_found = any(char in output for char in ['%', '$', 'x', 'version'])
return {
'score': 1.0 if metrics_found else 0.0,
'reason': 'Contains metrics' if metrics_found else 'Missing metrics'
}Upload the grader function through the Evals UI. The platform runs it on every test case and shows aggregate results.
My first eval run scored 72% on the factual category. The agent was missing recent news because the web search only looked at the past week. I changed the time range to two weeks and the score jumped to 89%.
Set up automated evaluations by enabling "Run on every deployment". This prevents regressions when you modify the workflow. I caught a bug this way where I accidentally deleted the filter node and the agent started returning unrelated articles.
Trace grading visualizes each step of the agent's execution. Click into any failed test case and you'll see which node produced incorrect output. For a question about pricing, the trace showed the web search returned general articles instead of pricing pages. I added a search query modifier that appends "pricing" to relevant questions.
Link to section: AgentKit vs Alternative FrameworksAgentKit vs Alternative Frameworks
I've used LangGraph, CrewAI, and AutoGen on previous projects. Each has strengths depending on your use case. Here's what I found after rebuilding the same agent in all four frameworks.
LangGraph gives you maximum flexibility. You define the state as a Python class and create nodes as functions. The graph structure is explicit in code:
from langgraph.graph import StateGraph
workflow = StateGraph(AgentState)
workflow.add_node("search", search_news)
workflow.add_node("summarize", summarize_articles)
workflow.add_edge("search", "summarize")This approach works great for complex logic with branching paths and conditional edges. But you're writing more code. My LangGraph implementation took 450 lines compared to zero code with AgentKit's visual builder.
LangGraph integrates tightly with open-source reasoning models through LangChain. If you need to swap between different LLM providers or run local models, LangGraph makes that easier.
CrewAI structures agents around roles and tasks. You define a crew of agents, each with a specific job:
from crewai import Agent, Task, Crew
researcher = Agent(
role='Tech News Researcher',
goal='Find recent AI announcements',
backstory='Expert in AI industry trends'
)
task = Task(
description='Search for AI news from October 2025',
agent=researcher
)
crew = Crew(
agents=[researcher],
tasks=[task]
)CrewAI excels at multi-agent scenarios where different agents collaborate. For my single-agent use case, it added unnecessary complexity. I spent more time configuring agent interactions than building the actual workflow.
AutoGen from Microsoft uses an actor framework with conversational agents. You create agents that talk to each other:
from autogen import AssistantAgent, UserProxyAgent
assistant = AssistantAgent("assistant")
user_proxy = UserProxyAgent("user")
user_proxy.initiate_chat(
assistant,
message="Find AI news from October 2025"
)AutoGen is fast to prototype. I got a working agent in 30 minutes. But debugging multi-turn conversations is hard. When agents get stuck in loops or produce nonsense, you have to add explicit termination conditions and guard rails.
AgentKit sits between no-code simplicity and code flexibility. For straightforward workflows with linear or lightly branching logic, the visual builder is faster. For highly dynamic agents that need custom code at every step, LangGraph wins. For teams with non-technical members who need to modify agents, AgentKit's visual approach lowers the barrier.
I'd pick AgentKit for 70% of business use cases. LangGraph for research projects or complex agentic systems. CrewAI when you genuinely need multiple specialized agents working together. AutoGen for rapid prototyping or educational demos.
Link to section: Real Results from Production DeploymentsReal Results from Production Deployments
Ramp reported a 70% reduction in iteration cycles after switching to Agent Builder. What used to take months of custom orchestration, code reviews, and manual testing now ships in two sprints instead of two quarters. Their buyer agent went from blank canvas to production in a few hours.
LY Corporation in Japan built a work assistant agent in under two hours. The visual interface let engineers and subject matter experts collaborate directly on the workflow design. That cross-functional input would have required multiple meetings and documentation handoffs with traditional development.
I tracked metrics on my research agent over two weeks of production use. The agent processes about 100 articles daily and surfaces 8-12 with meaningful metrics or version announcements. Before AgentKit, I ran a cron job with Python scripts that broke every time a news site changed their HTML structure. The agent's web search and summarization tools handle layout changes gracefully.
Average latency per article is 3.2 seconds from search to final summary. That breaks down to 0.4s for web search, 1.8s for content fetch, 0.9s for GPT-5 summarization, and 0.1s for filtering. The web search and content fetch happen in parallel after the first loop iteration, so real-world latency is closer to 2.1s per article.
Token usage runs about 1,200 input tokens and 400 output tokens per article. At GPT-5 pricing of $1.25 per million input tokens and $10 per million output tokens, that's $0.0055 per article. Processing 100 articles daily costs $0.55, or $16.50 per month. Add $0.30 for web search calls and the total is under $17 monthly.
I tried the same workflow with GPT-4o to save costs. Input tokens dropped to $0.50 per million and output to $5 per million. Monthly costs fell to about $9. But summary quality dropped noticeably. GPT-4o missed metrics in headlines and occasionally returned generic summaries instead of extracting specific numbers. The extra $8 per month is worth it for my use case.
Link to section: Common Issues and How to Fix ThemCommon Issues and How to Fix Them
Agent Builder threw a "Workflow validation failed" error when I tried to deploy a workflow with a loop that had no exit condition. The error message was vague. I clicked into the loop node settings and found the issue: I forgot to set a maximum iteration count. Set it to 50 and the validation passed.
ChatKit wasn't rendering in my Next.js app. The browser console showed a hydration error. The problem was server-side rendering. ChatKit only works client-side because it manages WebSocket connections for streaming. Wrap it in a dynamic import with SSR disabled:
import dynamic from 'next/dynamic';
const ChatKit = dynamic(
() => import('@openai/chatkit').then(mod => mod.ChatKit),
{ ssr: false }
);Evaluations kept failing with timeout errors. My test dataset had questions that triggered long web searches. I increased the timeout in the eval configuration from 30 seconds to 90 seconds. That fixed most failures, but a few edge cases still timed out. I added a timeout node in the workflow itself that cancels execution after 60 seconds and returns a fallback response.
File uploads through ChatKit failed silently. No error message, no file attached to the agent input. The issue was file size limits. ChatKit defaults to 10MB max. I needed to upload PDFs up to 50MB. Update the maxFileSize prop:
<ChatKit
maxFileSize={50 * 1024 * 1024}
{...otherProps}
/>Remember that larger files consume more storage. ChatKit storage costs $0.10 per GB-day starting November 1, 2025.
Guardrails were blocking legitimate inputs. I enabled PII detection to mask sensitive information like email addresses and phone numbers. But it was also flagging technical terms that looked like IDs. I adjusted the confidence threshold from 0.8 to 0.95:
{
"guardrails": {
"pii_detection": {
"enabled": true,
"confidence_threshold": 0.95,
"mask_output": true
}
}
}That reduced false positives by 80% without missing actual PII.
Link to section: Pricing Breakdown and Cost OptimizationPricing Breakdown and Cost Optimization
AgentKit doesn't have a flat subscription fee. You pay for what you use: model inference, tool calls, and storage. The pricing structure has several components.
Model usage is the big one. GPT-5 costs $1.25 per million input tokens and $10 per million output tokens. A typical agent interaction with a 500-token prompt and 200-token response costs about $0.0026. If your agent handles 1,000 interactions daily, that's $2.60 per day or $78 per month just for model inference.
Tool usage adds up faster than you expect. The Code Interpreter costs $0.03 per session. File Search storage is $0.10 per GB per day. Web Search costs $10 per 1,000 calls. My research agent makes 3,000 web search calls monthly, which is $30. That's more than the model inference costs.
ChatKit storage starts charging on November 1, 2025 at $0.10 per GB-day. If users upload 100GB of files and you keep them for a month, that's $300. Implement a retention policy that deletes old uploads after 30 days. I wrote a cron job that runs daily:
import os
from datetime import datetime, timedelta
cutoff = datetime.now() - timedelta(days=30)
for filename in os.listdir('uploads'):
filepath = os.path.join('uploads', filename)
if os.path.getmtime(filepath) < cutoff.timestamp():
os.remove(filepath)This keeps storage costs under $10 monthly for my use case.
To reduce model costs, I switched parts of the workflow to GPT-4o mini. Simple classification tasks and data extraction don't need GPT-5. The mini model costs $0.15 per million input tokens and $0.60 per million output tokens. For the filter node that checks if summaries contain metrics, I changed from GPT-5 to GPT-4o mini and saved 90% on that step.
Caching can cut costs for repetitive queries. OpenAI's prompt caching lets you mark portions of the prompt that don't change:
response = openai.chat.completions.create(
model='gpt-5',
messages=[
{
'role': 'system',
'content': 'You are a tech news summarizer...',
'cache_control': {'type': 'ephemeral'}
},
{'role': 'user', 'content': article_text}
]
)The system message gets cached for 5 minutes. Subsequent requests within that window skip processing those tokens and you pay 10% of the usual rate. For my agent that processes batches of articles, this cut input token costs by 60%.
Link to section: When to Use AgentKit vs Building CustomWhen to Use AgentKit vs Building Custom
AgentKit makes sense for workflows with 3-20 steps, limited branching, and standard integrations. If your agent needs to search the web, process documents, call APIs, and transform data, AgentKit handles that out of the box.
Don't use AgentKit if you need fine-grained control over execution, custom retry logic, or integration with proprietary systems not in the Connector Registry. I tried building an agent that interfaced with an internal GraphQL API. AgentKit's connector system required writing a custom MCP server, which took longer than just coding it in Python with LangGraph.
Skip AgentKit for highly dynamic workflows where the steps themselves change based on runtime data. If your agent needs to decide at execution time whether to take 5 steps or 50, code gives you more flexibility. Agent Builder's graph structure is somewhat static.
Use AgentKit when speed matters more than perfect optimization. You can ship a working agent today instead of next month. As AI-powered development tools become more prevalent, the ability to iterate quickly on agent designs will separate successful products from those stuck in development.
For teams with non-technical stakeholders who need visibility into agent logic, the visual workflow is invaluable. Product managers and designers can review the agent's behavior without reading code. That's harder with LangGraph or AutoGen where the logic lives in Python functions.
AgentKit doesn't replace framework-based development. It complements it. Build your first version in AgentKit to validate the concept. If you hit limitations, export the workflow and reimplement in code. OpenAI plans to add a Workflows API that lets you instantiate Agent Builder workflows programmatically, giving you the best of both approaches.

